LLM agents increasingly learn not from numerical rewards, but from language: a critique, a hint, an explanation of what went wrong. We give this setting a precise mathematical footing, introduce a complexity measure — the transfer eluder dimension — that says when language feedback makes learning easier, and derive a provably no-regret algorithm, HELiX, that turns the theory into an inference-time strategy for real LLMs.
01Why language feedback is different
Classic sequential decision-making — bandits, reinforcement learning — runs on a thin signal: a scalar reward. You take an action, you get a number, you nudge your policy. But the world rarely talks to us in numbers. A reviewer doesn't hand back a $0.7$; they say "the summary is mostly accurate, but it overlooks the main character's motivation."
That sentence does something a reward cannot: it tells you what is wrong and where to look. A scalar of $0.7$ leaves you guessing across the whole action space; the critique points straight at a fix. This is the premise of Learning from Language Feedback (LLF) — a paradigm introduced as an interactive benchmark by Cheng et al. (2023)1: the agent never sees the reward at all. It must maximize a hidden reward using only natural-language feedback.
A coin that talks
Here is the smallest example that shows why feedback is more than a disguised reward. A coin has unknown head-probability $\eta \in \{0,\,0.1,\,0.5\}$. You guess $a \in \{H, T\}$. The environment says "match" or "miss"; the hidden reward is $1$ if you were right.
With binary feedback, "match/miss" carries exactly one bit — the same as the reward. But enrich it to "miss — your guess was too optimistic; the coin seems tail-heavy" and suddenly a single observation can rule out whole families of hypotheses. The information isn't in the reward; it's in the structure of the sentence. The question this paper answers is: how do we quantify that extra information, and how do we provably use it?
Feedback shapes difficulty — exponentially
Consider building a hidden $L$-step reasoning chain, where each step is drawn from a set $\mathcal{S}$ of possibilities and the reward is $1$ only if every step is correct. The same task becomes wildly easier or harder depending on what the feedback tells you:
| Feedback type | What it tells you | Learning complexity $\dim_{TE}$ |
|---|---|---|
| Reward | whether all steps are correct1-bit binary reward | $O(|\mathcal{S}|^{L})$ |
| Explanation | index of the first wrong step | $O(|\mathcal{S}|\,L)$ |
| Suggestion | correction for the first mistakeonline teacher correction | $O(L)$ |
| Demonstration | all the correct stepsonline teacher demonstration | $O(1)$ |
Reward-only learning is exponential in the chain length $L$ — you essentially enumerate every sequence. Feedback that merely localizes the first error collapses this to a product; a constructive correction removes the dependence on $|\mathcal{S}|$ entirely; and a demonstration solves it in one shot. The richer the language, the flatter the problem. This is the engine of the whole paper.
02The framework: hypotheses, verifiers, and a new dimension
To make "information in feedback" rigorous, the paper introduces three objects. Each one replaces a familiar piece of the bandit machinery with a language-native analogue.
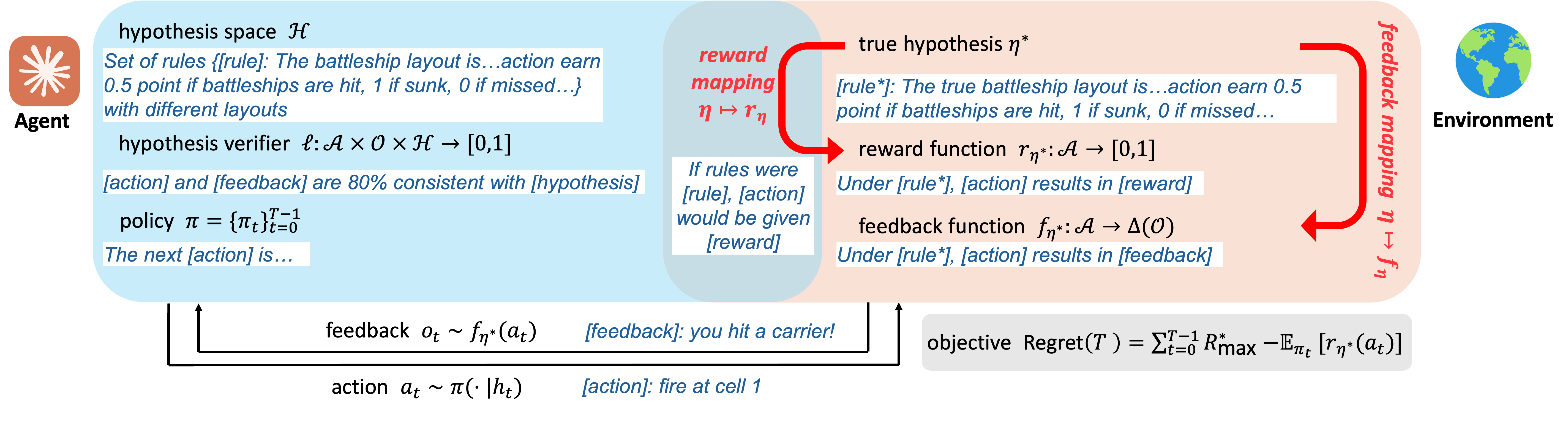
1 · The hypothesis
Instead of a parameter vector $\theta^*$, the environment is described by a hypothesis $\eta \in \mathcal{H}$ — a piece of text rich enough to pin down both how rewards and how feedback are generated. A hypothesis might be a user's taste profile, a game's rules plus its hidden board, or code. The reward mapping $\eta \mapsto r_\eta$ is assumed known (an LLM-as-judge can score an action given the rules); the true hypothesis $\eta^*$ is unknown. This mirrors a linear bandit's known feature map and unknown parameter — but in language.
2 · The hypothesis verifier
How does the agent extract information from a sentence? Through a hypothesis verifier, a loss $\ell(a, o, \eta) \in [0,1]$ that asks: is hypothesis $\eta$ consistent with feedback $o$ on action $a$? Crucially this is not a reward model and not a correctness oracle. It never certifies that $\eta$ is true — it only flags when $\eta$ has been contradicted by what was observed. Consistent ⇒ $\ell = 0$; incompatible ⇒ a positive penalty. Feedback is assumed unbiased: the true hypothesis is always among the loss-minimizers.
3 · The transfer eluder dimension
The headline construct builds on the eluder dimension of Russo & Van Roy (2013)2 — a way to measure how many times a reward function can still surprise an optimistic learner before its value everywhere is pinned down. That number controls how fast classic reward-based exploration converges. The transfer eluder dimension $\dim_{TE}$ measures something subtler: not how many surprises remain in reward space, but how effectively consistency-on-feedback transfers into certainty about reward. An action is transfer-independent of past actions if two hypotheses can agree on all the feedback seen so far yet still disagree sharply about its reward.
03HELiX: turning the theory into an algorithm
HELiX — Hypothesis Elimination using Language-informed eXploration — is a UCB-style algorithm that follows the optimism in the face of uncertainty principle, but over a space of text hypotheses. At each step it keeps a confidence set $\mathcal{H}_t$ of hypotheses still consistent with the feedback, then makes one of two moves:
- Exploit when there is consensus: if some action is simultaneously optimal for every surviving hypothesis, take it. (Disagreement about the world doesn't matter if everyone agrees on what to do.)
- Explore otherwise: take the most optimistic action — the one some surviving hypothesis rates highest — to gather information that prunes the set.
The consensus check is a genuine departure from textbook UCB. It acts as a stopping criterion: once the candidates agree on the best action, HELiX stops exploring even if it is still uncertain about the exact rewards. This is exactly the behavior you want when feedback reveals the optimal action directly without revealing the full reward structure.
The LLM implementation
The theoretical algorithm searches over an exponential hypothesis space — impossible in practice. The key practical contribution is approximating it with three LLM calls per step, yielding an inference-time strategy that is a principled alternative to a single chain-of-thought (CoT):
- Sample hypotheses + actions. Prompt the LLM for $N$ diverse "thinking traces" (hypotheses) consistent with the history, each with its best action. The LLM implicitly acts as the verifier, filtering inconsistent hypotheses.
- Build the score matrix. Use an LLM reward-mapping $R_{\text{LLM}}(\eta, a)$ to score every candidate action under every hypothesis, forming a matrix $S_t$.
- Decide. Read the explore/exploit decision off $S_t$ via row-wise argmaxes.
Why structure exploration this way rather than trust the model to explore on its own? Because whether LLMs can balance exploration and exploitation in context is far from settled — studies that probe them on bandit-style decision problems find the ability uneven and often in need of explicit scaffolding. HELiX supplies that scaffolding as an external rule inspired by a provable algorithm instead of hoping it emerges from a single CoT.
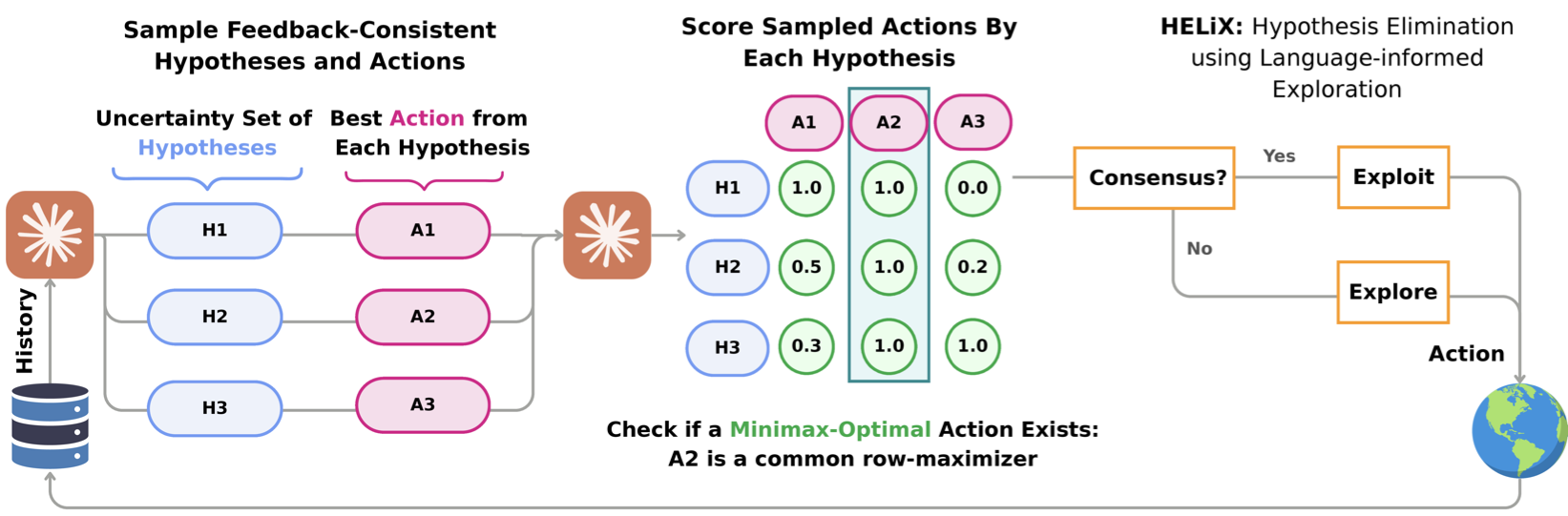
The decision rule, precisely
The explore/exploit choice is a small piece of linear algebra on $S_t$. For each hypothesis (row), take the set of highest-scoring actions. Then:
- Consensus (Exploit): if the intersection of these row-argmax sets is non-empty, that shared action is chosen — it is optimal for everyone.
- No consensus (Explore): if the intersection is empty, eliminate all but the highest-scoring hypotheses, then pick the action with the globally highest score.
- Tie-breaking via re-scoring: ties are broken by subtracting each action's average score under a random reference policy $\pi_{\text{ref}}$ — an advantage that cancels an LLM's per-hypothesis scoring quirks and favors discriminative hypotheses over permissive ones (e.g. "fire along the edge" beats "fire anywhere"). Remaining ties prefer actions generated earlier.

04Play the environments
HELiX is evaluated on language-feedback games where the agent never sees a reward — only words and a partially-revealed map. Play them yourself to feel the information problem the agent faces. The hidden reward is tracked silently and revealed in the log, exactly as in the paper.
05Build a score matrix, step by step
This is the heart of HELiX. The board below is the same Battleship board you played above — fire a shot on either one and both update. Walk through the algorithm one stage at a time and watch the score matrix get built and read. The "LLM" here is a transparent heuristic so you can see exactly why each score lands where it does — but the mechanism (sample → score → consensus check → explore/exploit → tie-break) is exactly the paper's.
Tip: fire a few shots (here or in the game above) to grow a hit-streak. When the hypotheses point in different directions, HELiX explores; when they all agree on the same next cell, it exploits. Any shot resets the reasoning so you can re-run it on the new board.
06Does it work?
Across Wordle, Battleship, and Minesweeper, HELiX consistently beats a chain-of-thought baseline and its own ablation without the consensus exploitation step. The gap is largest exactly where information-gathering matters most — Minesweeper — confirming that strategic exploration, not raw LLM cleverness, is doing the work. All runs use Claude 3.5 Sonnet (v2).
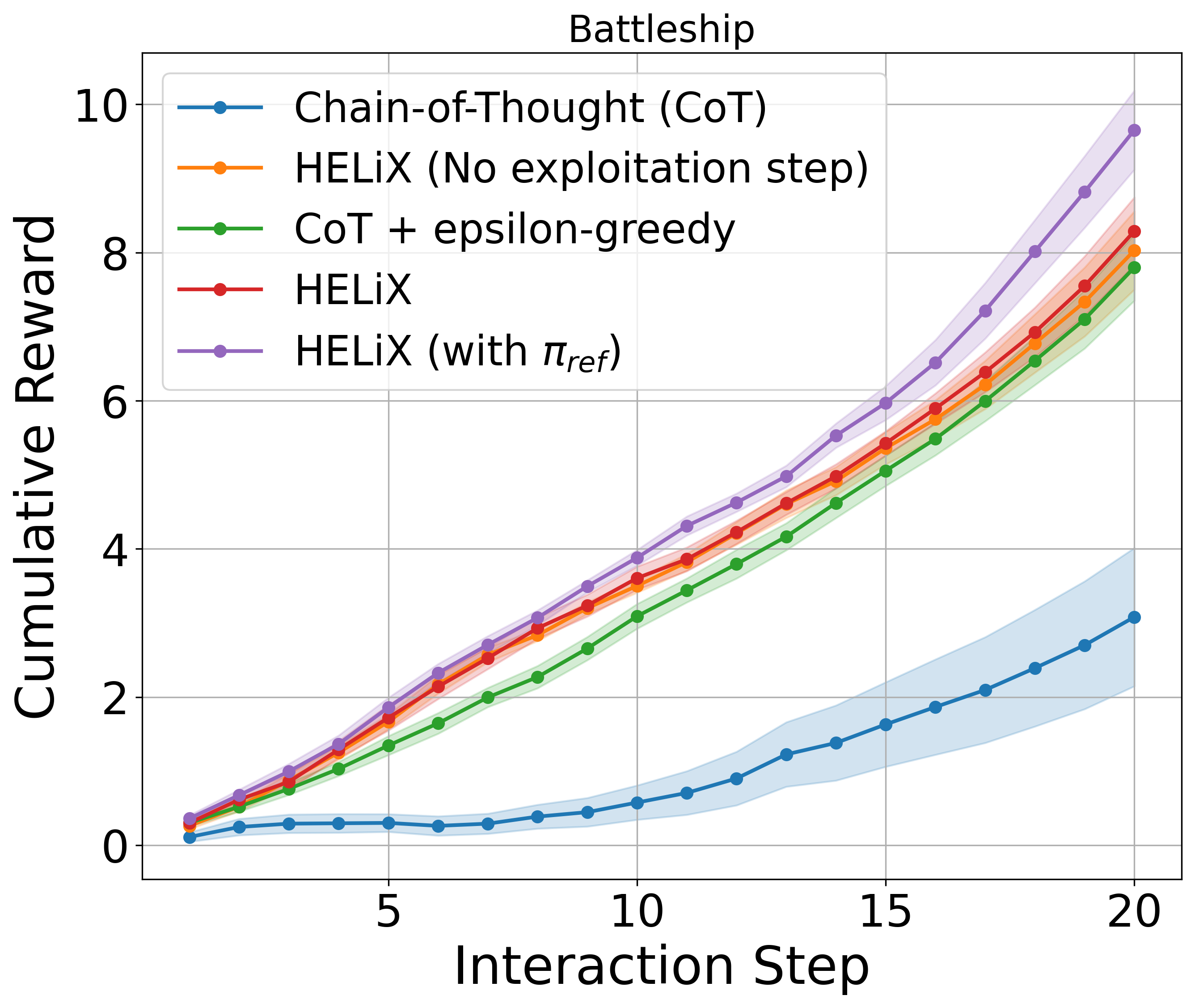
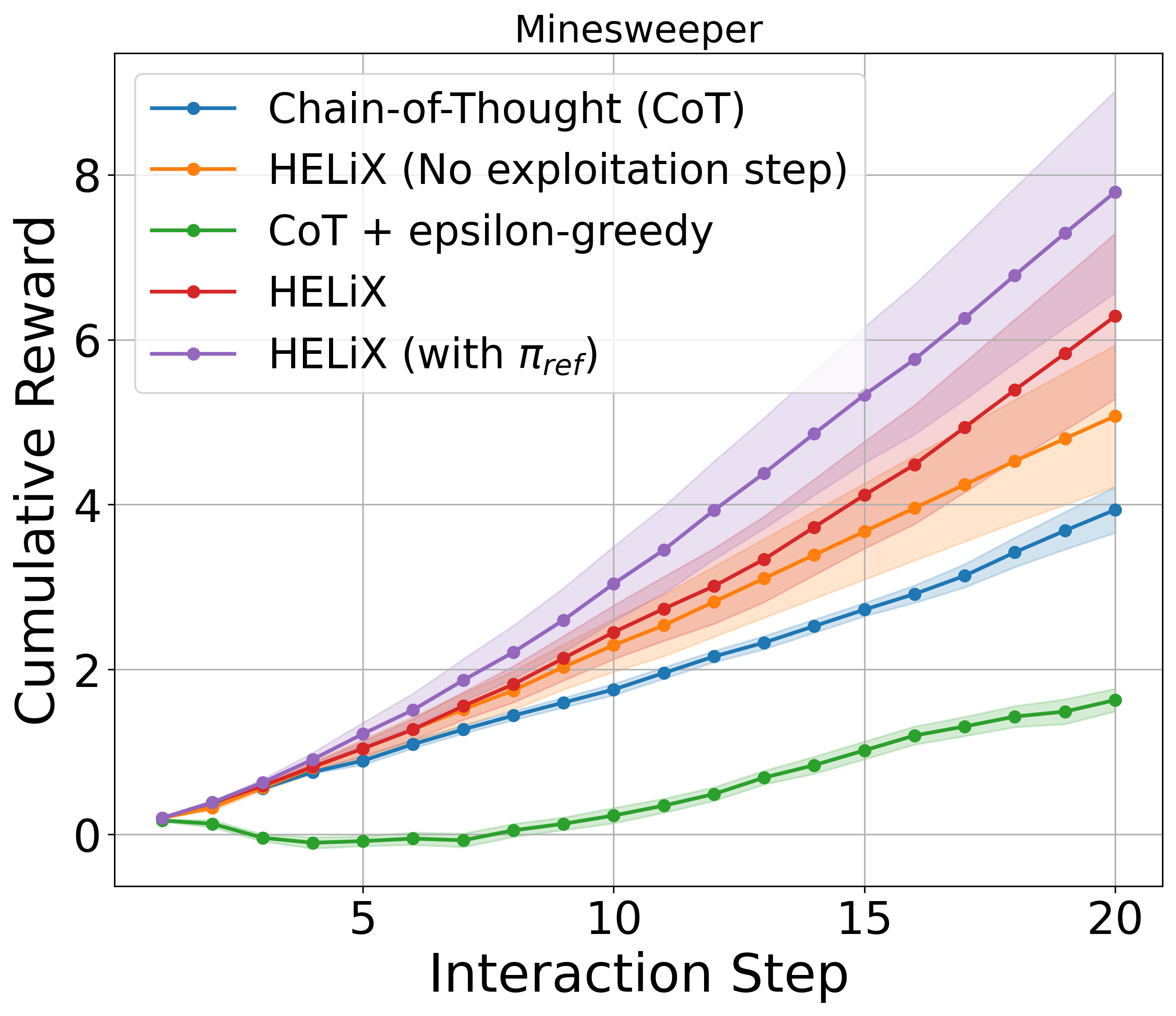
A note of honesty from the authors: HELiX assumes the LLM can pick a good action under a given hypothesis and can score actions fairly across hypotheses. These assumptions don't hold for every model or task. The contribution is less "a finished agent" than a specification of the properties an LLM must have to be a principled language-feedback learner — and a guarantee that, if it has them, learning is efficient.
07Takeaways
- Language feedback is a first-class signal, not a disguised reward. The transfer eluder dimension quantifies how much it helps.
- Informative feedback is never worse than reward, and can be exponentially better — formalized via $\dim_{TE} \le \dim_E$.
- HELiX makes this constructive: sample hypotheses, cross-score them against actions, exploit on consensus and explore on optimism — with a sublinear regret bound.
- It runs on today's LLMs as an inference-time alternative to chain-of-thought, and it wins on language-feedback games.
08References & further reading
- C.-A. Cheng, A. Kolobov, D. Misra, A. Nie, and A. Swaminathan. LLF-Bench: Benchmark for Interactive Learning from Language Feedback. arXiv:2312.06853, 2023. Introduces the LLF paradigm and benchmark this work formalizes — agents that learn interactively from natural-language feedback in place of rewards.
- D. Russo and B. Van Roy. Eluder Dimension and the Sample Complexity of Optimistic Exploration. Advances in Neural Information Processing Systems (NeurIPS), 2013. Introduces the eluder dimension, the reward-space complexity measure that the transfer eluder dimension generalizes.